
我們在 Day 19 和 Day 20 曾提到使用 Partitioned table 和 Clustered table 不僅能夠提升查詢效能,進而能夠減少費用(特別在以量計價模式下更有感覺),甚至降低故障。
其實 Partitioned table 和 Clustered table 都能夠提升查詢效能,並且在概念上,都是對一張大表去做切片,能更快從切片找到我們要的資料,而不用掃描整張大表。
你應該會有點疑惑,那麼兩者到底有什麼差異呢?
其實就是根據資料的屬性,再決定要設置 Partitioned table 還是 Clustered table !
當然,Partitioned 和 Clustered 也是可以同時設定在同一張表的,設置得當的話,效能更好。
分區表,顧名思義就是將一張大表,使用我們定義的規則去把它分區切成一張張小表,而這個分區的規則可以是時間或是整數,而時間粒度可以分為按年、按月、按日、按小時去做分區,分區的規則只能有1個,不像 clustered table 最多可以有 4個。
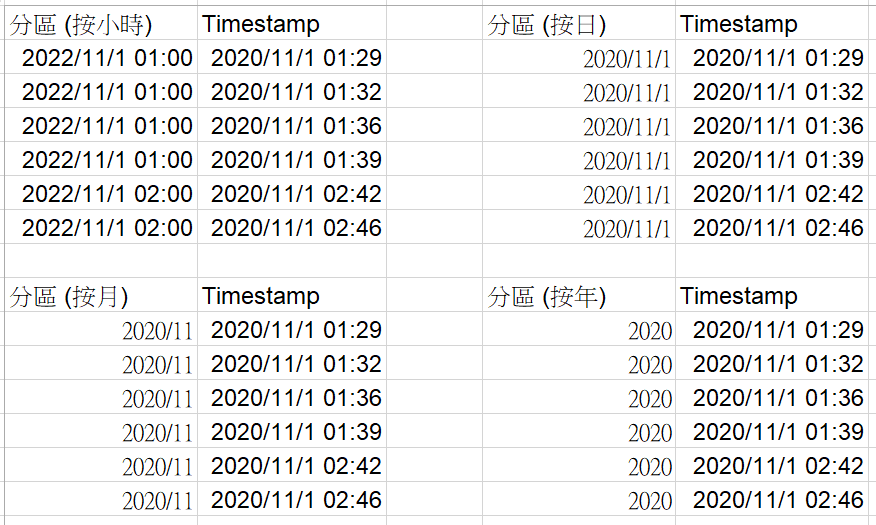
假設我們已經建立Partitioned table,並且使用以下查詢:
SELECT event_type
FROM test_table
WHERE date = ‘2020-11-03’;
BQ 就只會查看藍色標起來的數據。
使用分區的方式要留意,Partitioned table 存在配額限制,每個表最多只可以有 4000個分區,這句話是什麼意思呢?
舉個例子:
情況一: 假設我們使用按日的方式去做分區表,那麼我們最多可以設置十年左右的數據。
365 * 10 = 3650 < 4000
情況二: 假設我們使用按小時的方式去做分區表,那麼我們這張表最多可以存放五個月左右的數據。
24 * 30 * 5 = 3600 < 4000
舉以上兩個例子主要是想提醒大家,未來在設計分區表的時候,要記得分區表存在分區 4000的配額限制。
Clustered table 硬翻成中文實在太難唸了,我們還是就用英文吧! Clustered table 顧名思義就是將一張大表去做分群, 而這個分群最多可以設置 4 個 column。 還記得我們在 Day 07 曾提到 BigQuery 的基本架構可以分為儲存和運算,BQ背後儲存的方式就是分散式運算,當我們沒有設置任何 Clustered columns的時候,我們的資料是被隨機排序的。
當有設置 Clustered columns的時候,情況就不同了,BQ會對我們的資料作排序,並且排序的順序,是按照我們給的columns 順序。
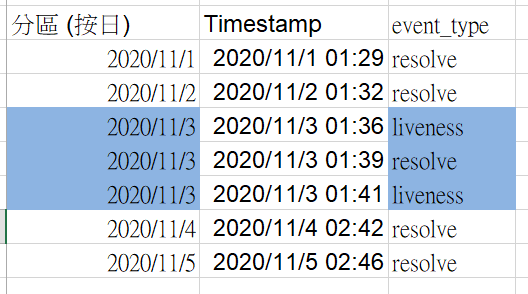
假設我們已經建立Clustered table,執行範圍如藍色:
SELECT event_type
FROM test_table
WHERE event_type = ‘liveness’;
使用 clustered table 的注意事項我們在 Day 20 曾提到過,因為 BQ 是在執行後才去做 cluster,因此費用無法在執行前被預估。
假設執行以下查詢:
SELECT event_type
FROM test_table
WHERE TTimestamp = ‘2020-11-03’ and event_type = ‘liveness’;
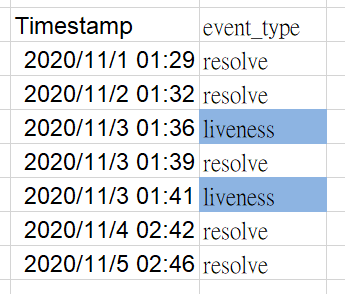
如果我們只建立Partitioned table,查詢範圍如藍色:
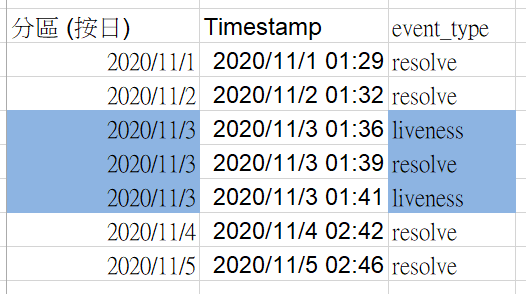
如果我們做建立Partitioned table 加上 clustered table,查詢範圍如藍色:
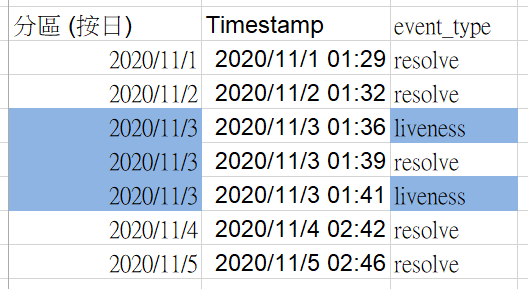
*註: 結合使用的話,BQ 的背後是先做 Partitioned,再做 clustered。
| 比較 | Partitioned table | Clustered table |
|---|---|---|
| 配額限制 | 最多只能設置 4000 個分區 | 無 |
| 可設置 column 數 | 只能設置 1 個 | 可以設置 4 個,並按照設置順序去排序 |
| 執行前可否預估費用 | 執行前可以知道費用 | 執行前無法知道費用 |
| 使用時機 | 1.希望在查詢前知道費用 2.需要做額外的管理,比如設置分區的到期時間 | 1. 資料欄位屬於高基數 2. 執行前無須嚴格的費用保證 3. 經常對多個欄位做 過濾 或是 使用 聚合函數。 |
*註: 高基數: 數據列中獨一無二的數量。
不論是 Partitioned 或 clustered 均可以節省效能費用,甚至也可以結合Partitioned 和 clustered,設置得當的話,效果更好。
Introduction to partitioned tables
Introduction to clustered tables
配額限制
